
From Hive MetaStore to Unity Catalog
Databricks Migration

Earlier this year, we aimed to move to Unity Catalog from hive metastore. The reason for better data governance is the features of Databricks Alerts, Lakehouse Monitoring, Model Serving, etc. We tried in 2023 but hit an impasse where the unity catalog system wasn't ready for our use cases, and our approach was too broad. So, earlier this year, we decided to try again. Why not?
When approaching considerable changes in the data platform, you have to understand the result or the intended consequence and why we are doing it. Comparing old and new ways is a good way to start thinking about where the problems are.
To keep it simple, what are we gaining from UnityCatalog vs Hive Metastore?
The most significant change for us was one metastore for three environments. Then you have the Unity Catalog object model, which we didn't have in hive metastore.
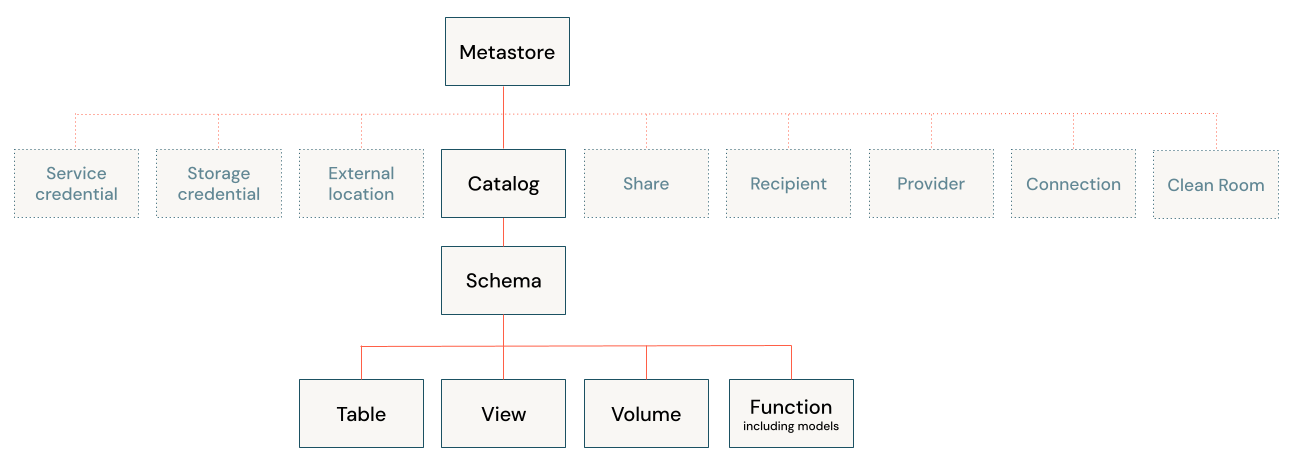
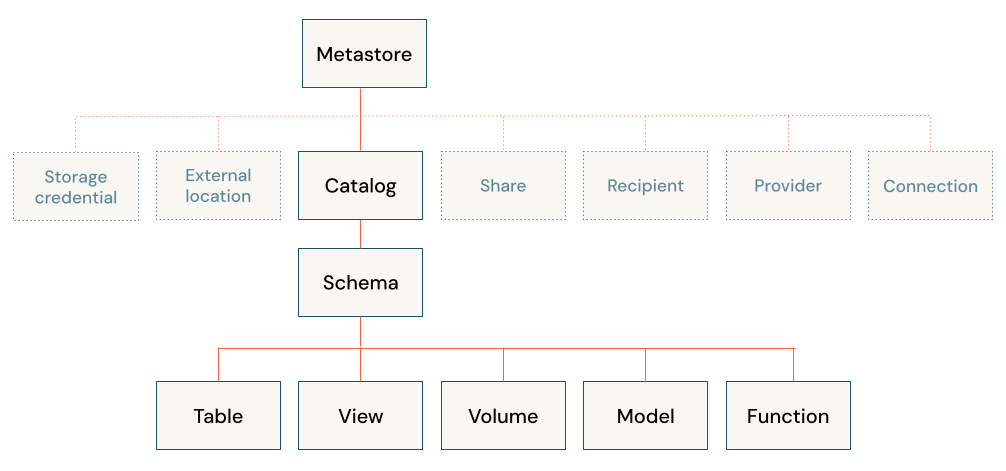{kind=link}
So to separate our environments of test/qa/prod, we decided to go the prefix route where each catalog, for example, product, will have a test_ qa_ and the product wouldn't have a prefix, so users using the data platform wouldn't have to think about the environment and use the name without a prefix, making it easier to search and easy to hide the other environments from the prod workspace.
The plan's first iteration involved migrating each data pipeline individually and deleting the hive metastore table. What do I mean by migrating? It means moving each data pipeline, backfilling, and validating each new Unity Catalog Table.
One of the issues we faced when we decided to move it first was this migration plan. It created more anxiety, and it wasn't a suitable environment for a very heavy/detailed process. I proposed copying each data pipeline into its Unity Catalog counterpart and focusing first on the reading/writing part of the problem. Then, we can validate as a whole, focusing primarily on validating.
The hive metastore became very messy because tables had no purpose or useability. We made Table/Catalogs/Volumes part of our codebase(IaC). That way, we know the tables, their DDL, and what domain they are from for keeping the lake clean, and we can review them in code reviews.
The most significant part of the move was our implementation of DeltaTable python SDK with hive metstore. So I decided let's create a new one with the learning of the previous one and start from scratch having these ManagedTables and ManagedVolumes handle all the metadata/names/history and have a client, either a ManagedTableClient do the reading/writing/merging/CDC as well with ManagedTableVolume.
This new Client and Table Oject decoupled our previous error of having the client have the metadata and be able to do operations on the table.